
# chatGLM的本地部署
前段时间,清华大学开源了国产的双语对话语言模型chatGLM。和openAI的chatGPT相比还是有很多不足之处,但是它体量小,能够在消费级显卡上部署。
在这里主要介绍本地部署的过程和我遇到的问题。
首先克隆仓库到本地
git clone https://github.com/THUDM/ChatGLM-6B.git
使用 pip 安装依赖:
pip install -r requirements.txt
然后运行命令行 Demo
python cli_demo.py
程序会自动下载模型和剩余的依赖
假如之后想要删除,模型的安装目录在:C:\Users\[你的用户目录]\.cache\huggingface\hub
如果运行成功没有报错,你应该会看到这个界面
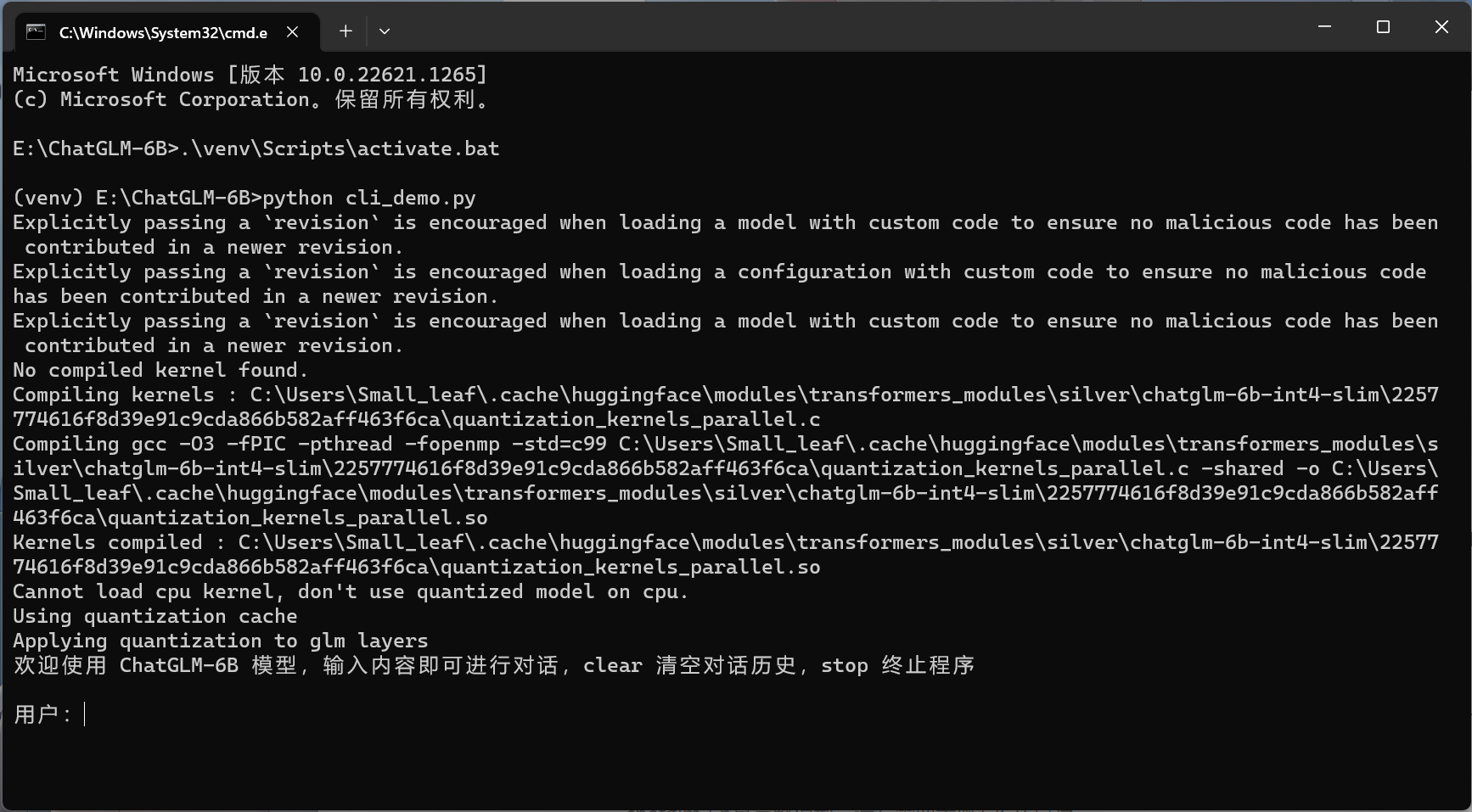
但是部署过程一般来说不可能这么顺利
你会遇到各种各样的问题
# 在安装时可能遇到的问题
# 显存较低
如果你的电脑显存较低(小于13GB),可以修改cli_demo.py文件中的:
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
将THUDM/chatglm-6b 修改为 THUDM/chatglm-6b-int4或者THUDM/chatglm-6b-int4-qe
chatglm-6b 是完整模型,运行需要大概13GB 显存。
chatglm-6b-int4 是 4-bit 量化模型,需要大概 5.2GB 的显存。
chatglm-6b-int4-qe是对Embedding量化后的模型,模型参数仅占用 4.3 GB 显存。
注意
仅仅是运行起来就需要5.2G的显存,后续的对话依然需要占用显存。比如我的RTX3060 Laptop,6G显存在进行两次左右的对话就会吃满显存然后直接爆掉,所以实际的实际体验可能并不能尽如人意。
# 'gcc' 不是内部或外部命令,也不是可运行的程序 或批处理文件。
这个报错的意思是在编译时缺少 gcc 编译器,从而导致了后续的错误。
gcc编译器可以前往官网 (opens new window)下载,这个视频有详细安装的教程。
如果在python虚拟环境中无法访问gcc编译器,可以尝试输入以下命令:
setx PATH "%PATH%;C:\MinGW\bin"
这里的“C:\MinGW\bin”是指安装gcc编译器的路径,你需要将其替换为系统上安装gcc编译器的实际路径。
这段命令的含义是设置环境变量 PATH,并将原来的 PATH 环境变量的值保留下来。
需要重新启动cmd来生效设置。
# AssertionError: Torch not compiled with CUDA enabled
这个报错提示 Torch 没有启用 CUDA 编译。如果你已经正确安装了CUDA,那可能是因为PyTorch的版本不支持
可以前往PyTorch官网 (opens new window)下载合适的版本。

你可以通过在CMD中输入nvcc --version来查看你的CUDA版本。
# 2023/03/29更新
silverriver (opens new window)大佬发布了裁减掉20K图片Token的模型,在不减小性能的情况下,占用更小的显存。 实测能从两次对话增加到五次以上的水平。 并不需要将他的仓库克隆过来,只需要将cli_demo.py文件中的
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
替换为
tokenizer = AutoTokenizer.from_pretrained("silver/chatglm-6b-slim", trust_remote_code=True)
model = AutoModel.from_pretrained("silver/chatglm-6b-int4-slim", trust_remote_code=True).half().cuda()
# 2023/04/06更新
官方采纳了silverriver (opens new window)的建议,直接在官方仓库移除了embedding中的image token。